Table of Contents
Synchronization (of identities)
The basic task of the synchronization is to ensure the correct state of the data on the end system and in IdM. Typically users´ accounts are considered as data. The correct state is defined both by the data in IdM (account management) and by the IdM configuration itself - usually by setting provisioning and synchronization on a given system.
Entities that supports sync
| Name | Entity name (DTO) | More details |
| Identity | IdmIdentityDto | Synchronization |
| Contractual relationship | IdmIdentityContractDto | Synchronization - contractual relationship |
| Time slices of contractual relationship | IdmContractSliceDto | Synchronization - time slices of contractual relationship |
| Tree | IdmTreeNodeDto | Synchronization - tree nodes |
| Role | IdmRoleDto | Synchronization of roles/groups |
| Role catalogue | IdmRoleCatalogueDto | Synchronization - role catalogue |
The usual synchronization process is as follows:
- Finding the changed accounts on the end system.
- Iteration of the changed accounts and evaluation of the situation for each account (account in IdM).
- Action performance for the situation found (e.g. creation of an identity in IdM).
- Running the subsequent operations (e.g. provisioning updating an account on the end system).
Situation
During the synchronization process, the situation in which the account can be found based on the state in IdM is evaluated for every account. Basic synchronization configuration means settings the type of action which should be done in a given situation.
The synchronization situations are fixed and they are the following:
Linked
The situation when a corresponding account exists to a given account on the system (AccAccount) in IdM.
In this situation, it is possible to proceed to the following actions:
- Update the entity - will update the identity linked to an account. The update is done based on mapping linked to the synchronization. At present, mapping enables to update the attributes of the identity itself, and also the attributes saved in the warehouse of advanced attributes as well as in coded warehouse. After saving an entity, standard provisioning will always be initiated.
- Update account - will initiate standard provisioning. Synchronization initiates an event, it does not do the provisioning itself.
- Remove link - will remove the link in IdM. meaning it will remove the account (AccAccount) and the links between the identity and the account (AccIdentityAccount). It does not modify the identity itself, does not initiate provisioning.
- Remove link and related roles - will remove the links like in the previous case but will also remove the identity roles which are linked to the corresponding (AccIdentityAccount). In other words, it will remove the roles which assigned a given account to the identity.
- Ignore - This action does not perform any active operation.
Not linked
Situation in which there is no link to a given account on the system (account in IdM), but an identity exists.
Since the link does not exist, in this case the identity has been found through a correlation attribute. A correlation attribute can be any attribute from the related synchronization mapping (the correlation attribute is mandatory).
For example, if you want to find (identify) identities in IdM based on the correspondence of the user name username and the account attribute login, you can use the following correlation attribute:
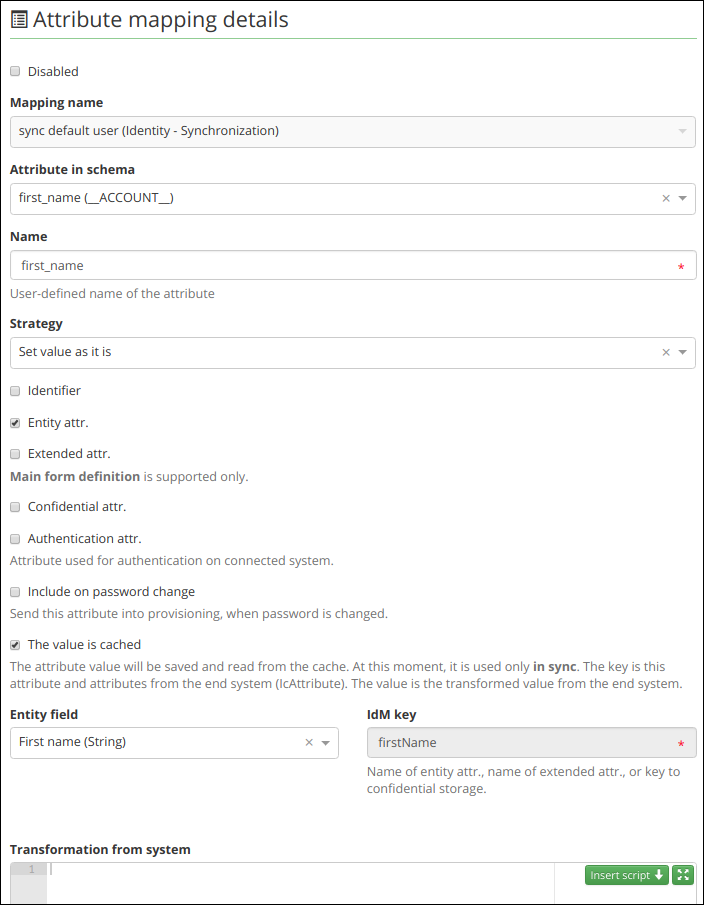
In this situation, it is possible to proceed to the following actions:
- Create link - will create a link in IdM, meaning it will create an account (AccAccount) and the link between the identity and the account (AccIdentityAccount). It does not modify the identity itself, does not initiate provisioning.
- Create link and update entity (since 8.0) - The link is created in the same way as in the previous case. In addition, the entity is updated. The update is done based on mapping linked to the synchronization. After saving an entity, standard provisioning will always be initiated.
- Create link and update account - The link is created in the same way as in the previous case. In addition, the account is updated on the end system, meaning that the event for running the provisioning is initiated.
- Ignore - This action does not perform any active operation.
Missing entity
Situation in which there is no identity in IdM to a given account on the system.
In this situation, it is possible to proceed to the following actions:
- Create entity - will create an identity and a link in IdM. The creation will be done according to the mapping set up in synchronization. Creation of an entity will initiate provisioning (account update).
- Ignore - This action does not perform any active operation.
Missing account
Situation in which there is no account on the end system to a given account in IdM (i.e. IdM expects that an account exists, but it in fact doesn't exist on the end system).
This situation may occur in case the connector supports the operation DELETE. This means that the connector is able to give information on which accounts have been deleted on the end system since the last synchronization. Yet this situation can be typically used in reconciliation when all the accounts in IdM are iterated overnight, verifying if an account exists on the end system - if it doesn´t a preset action is initiated.
In this situation, it is possible to proceed to the following actions:
- Create account - Synchronization will only initiate the event for the linked entity IdentityEventType.UPDATE that will initiate provisioning and so the account will be created on the end system.
- Delete entity - will delete the account in IdM, the link between the account and the identity, and the identity
- Remove link - will remove the link in IdM, meaning it will remove the account (AccAccount) and the links between the identity and the account (AccIdentityAccount). It does not modify the identity itself, does not initiate provisioning.
- Remove link and related roles - will remove the links like in the previous case but will also remove the identity roles which are linked to the corresponding (AccIdentityAccount). In other words, it will remove the roles which assigned a given account to the identity.
- Ignore - This action does not perform any active operation.
Connector synchronization vs. my own filter
Synchronization supports two basic modes of searching the accounts suitable for synchronization. The first mode is the use of synchronization mechanism which is provided directly by the connector. In such case, the method IcConnectorFacade.synchronization is called on the connector after synchronization.
The input of this method is the token defining where the synchronization should continue. In this case, the format of the token is defined directly by the connector (it can be a time mark, the order, …) If the token is empty, then the synchronization will be launched for all the accounts of the system.
The disadvantage of the synchronization in the connector is the impossibility to rule in details which of the accounts you want to synchronize (put together more complicated queries). On the contrary, the advantage is the possibility to use the operation DELETE . I. e. the situation in which the connector is able to report on its own which account has been deleted.
The second way is the Custom filter. This mode will compose the filter criterion first. This criterion is used to search account on the end system (IcConnectorFacade.search). The synchronization takes places above these results.
This mode can be activated (Use custom filter) and set on the Filter folder. The custom filter can be simply defined by choosing the attribute (Filter by attribute) by which you want to search, and the corresponding operation (Filtering operation).
To save the final token, it is necessary to determine the account attribute which contains it. To do this, you may use the item Token is contained in this attribute.
In case you need to create a more complicated filter criterion, it is possible to use this script. In the example below, you can find the situation when you want to filter by the chosen attribute and operation (the filter enters as variable into the script), but at the same time, you want to limit the result with one more condition. In this case, the condition is that all the results must have the attribute "lastname" equivalent to the "Doe" value.
import eu.bcvsolutions.idm.ic.filter.impl.IcFilterBuilder; import eu.bcvsolutions.idm.ic.api.IcAttribute; import eu.bcvsolutions.idm.ic.impl.IcAttributeImpl; IcAttribute attr = new IcAttributeImpl("lastname", "Doe"); return IcFilterBuilder.and(filter, IcFilterBuilder.equalTo(attr));
IcFilterBuilder provides the following operations:
- IcFilterBuilder.equalTo(…)
- IcFilterBuilder.contains(…)
- IcFilterBuilder.startsWith(…)
- IcFilterBuilder.endsWith(…)
- IcFilterBuilder.lessThan(…)
- IcFilterBuilder.greaterThan(…)
- IcFilterBuilder.or(…)
- IcFilterBuilder.and(…)
- IcFilterBuilder.not(…)
The output of this script must be an object of the type IcFilter . If the output is null, then the filter will not be applied and synchronization will be launched over all the accounts.
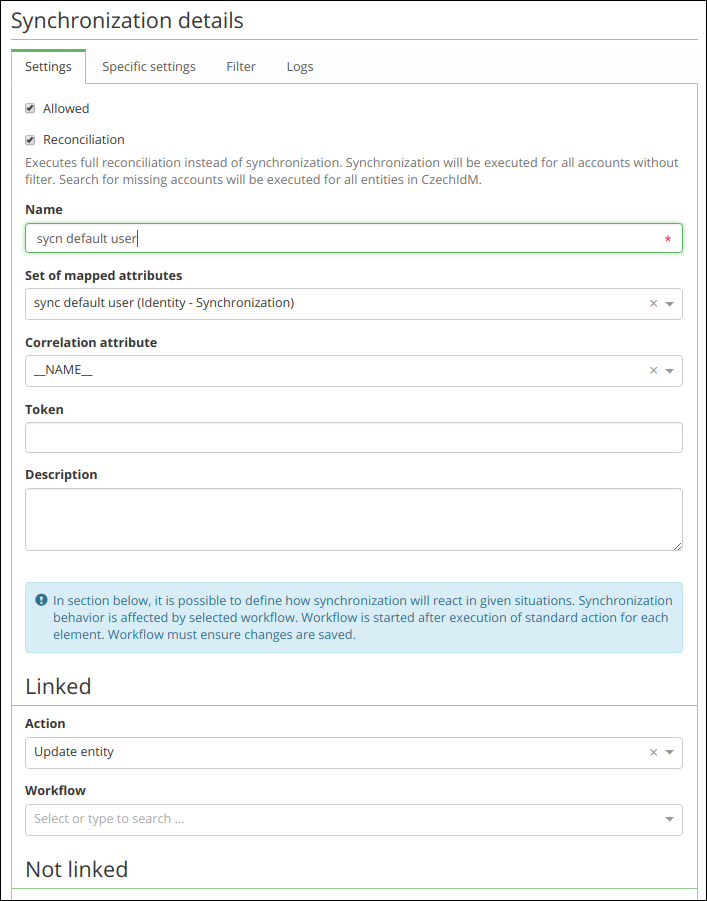
Workflow
In default state, synchronization can administer the identities (create, update, delete). Yet if you need a more complex solution, e.g. when you need to establish industrial relations, the standard synchronization mechanisms won´t be sufficient.
The solution is to use the own workflow which will perform the required operation (e.g. the creation of industrial relations mentioned above). The workflow can be set up separately for each situation.
If the synchronization finds out that workflow is set up in a given situation, it will launch it. In such case, the synchronization does not do anything with the given account anymore, i.e. all the active operations are performed by the workflow.
The workflow which should be possible to be used in synchronization, must satisfy several criteria. The first one is the category in which the workflow is included.
For synchronization, the workflow further expects the following input variables:
- uid (String), - entityType (enum SystemEntityType), + icAttributes (List of IcAttribute), - syncConfigId (UUID for SysSyncConfig), - actionType (String) - situation(String), + accountId(UUID), + entityId(UUID)
An example of how such workflow may look like is the following demonstration process (syncActionExampl). This process will establish an approval task for the administrator (admin) for every account of which the UID starts with test. All the other accounts will go through standard implementation according to the evaluated situation and the set-up action. The workflow is also showing that only one process resolving all the situations can exist.

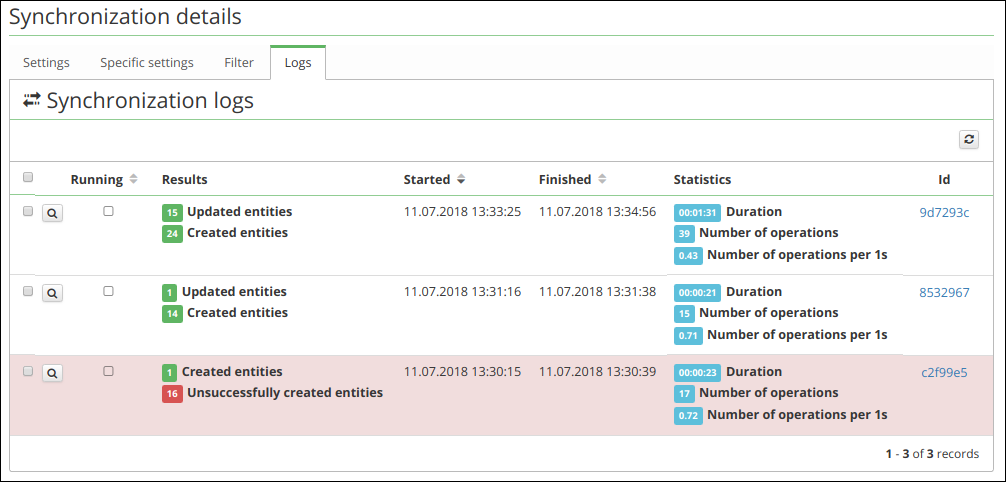
Logs
The synchronization logs are divided into three parts:
- SysSyncLog - The main log which is formed after the start of the synchronization. It contains the time of start, time of end, and the log for the whole process. It also contains the information if the synchronization has been launched and if some error occurred.
- SysSyncActionLog - is linked to the main log, categorizing the individual elements according to the action performed. It also contains the number of the iterations performed for each action.
The log may attain the following types of actions:
CREATE_ENTITY,
UPDATE_ENTITY,
DELETE_ENTITY,
LINK_AND_UPDATE_ACCOUNT, //create link and produce entity save event (call provisioning)
LINK_AND_UPDATE_ENTITY, // create link, update entity
LINK,
UNLINK,
UNLINK_AND_REMOVE_ROLE,
CREATE_ACCOUNT, // produce only entity save event (call provisioning)
UPDATE_ACCOUNT, // produce only entity save event (call provisioning)
LINKED, // situation (for IGNORE and WF sort)
MISSING_ENTITY, // situation (for IGNORE and WF sort)
UNLINKED, // situation (for IGNORE and WF sort)
MISSING_ACCOUNT, // situation (for IGNORE and WF sort)
IGNORE,
UNKNOWN;
Each of these types may attain the following states:
SUCCESS,
ERROR,
WARNING,
IGNORE,
WF
- SysSyncItemLog - is linked to the actions log. It records the course of the synchronization of each element. It contains the identifier and the name of the element.
Specific synchronization options

You can configure additional synchronization options for specific uses:
- Default role - The value can be any role in CzechIdM. This value is used in the case that the synchronization links an existing system account to an existing or a new identity in CzechIdM. If the default role is specified, this role will be assigned to the identity for its main valid contractual relationship. Then the link to the account will be created with the property Assigned by role set to the default role. If the default role is empty, the link to the account will be created as well, only without the property "Assigned by role".
- Assign default role to all valid contracts - If the default role is selected and this option is checked, then the default role will not be assigned to the main contract, but to all valid or in future valid contracts of the identity. As in previous step, the assigning is realized via role-request and this request is executed immediately without approving.
- The main use-case for this option is initial linking of accounts during the reconciliation of a system, where the accounts will be further managed by CzechIdM - e.g. LDAP, AD. The default role will be usually configured for provisioning on this system, see Provisioning - role and queue configuration.
- This option is supported in the following actions of the synchronization: Missing Entity → Create entity, Not Linked → Create link, Create link and update entity, Create link and update account.
- The role assignment skips an approval process - the corresponding role request will be processed Without approval.
- If the identity doesn't have any valid contractual relationship, the synchronization will take action based on the Behavior of the default role for inactive identities option (see below).
- Note that the role will be assigned to the identity regardless of other role assignments of the identity. So even if the identity already had the same role assigned, the role would be assigned again and the created account's link will be related to this new assignment.
- Behavior of the default role for inactive identities (since 9.2.3): This option is required in the case that a Default role (see above) is specified for the synchronization. If the synchronized identity doesn't have any valid contract, then the default role can't be assigned to it. So you must specify by choosing one of the following options, how the synchronization should behave in such situations:
- DO\_NOT\_LINK: The account won't be linked and the identity won't be updated or created at all. The result of processing this item is Ignore. Typically, you will use this option when you connect a system to IdM in which you expect some old unwanted accounts, and you don't want to manage them anymore.
- LINK\_PROTECTED: The account will be linked to the identity without the property "Assigned by role", but it will be put into the protected state. The length of the protection is based on the last expired contract of the identity and the Length of protection interval configured in the provisioning mapping for this system. Note that this can be in the past if you have a short protection interval, so the account can be deleted as soon as the task for deleting expired accounts (AccountProtectionExpirationTaskExecutor) starts. If the identity doesn't have any expired contract (it has no contracts, or only future contracts), the current date is used as the start of the protection. Typically, you will use this option if you connect a system to IdM in which you intentionally keep old accounts, and you want to have some control over these accounts by IdM (e.g. if the original owner got a new valid contract, the original account should be reused). This option requires an existing provisioning mapping with Account protection enabled, otherwise the synchronization wouldn't start.
- LINK: The account will be just linked to the identity without the property "Assigned by role". The result of processing this item is Warning, because such account is not managed by role assignment - it will exist as long as the corresponding identity exists regardless of its (in)activity. This option is for backward compatibility mainly, because such was the behavior in the versions < 9.2.3.
- After end, start the automatic role recalculation - After synchronization correctly ended recalculation of automatic role will be started.
- Create default contracts for new identities - If a new identity is created during synchronization, a default contract will be created for the identity. To use this feature, you must also enable creating default contracts in the application configuration (
idm.pub.core.identity.create.defaultContract.enabled=true).
Differential sync (process only differences)
The goal of differential synchronization is to update the synchronized entity only if at least one mapped attribute value has changed. This prevents unnecessary event creation in the system.
Differential synchronization only checks the values of the mapped attributes. Ie. if the attribute that we do not map in IdM changes in the source account, the differential synchronization will not detect the change and the entity will not be saved.
If differential synchronization evaluates that the account has not changed against to the entity in IdM, the account is marked as IGNORE (blue color) in the sync log.
In the picture below, only one change was detected.
Therefore, 18 elements are marked as IGNORE and one is marked as SUCCESS (green color):


How differential sync can be enabled?
Differential sync can be enabled on the detail of sync, where Process only differences have to be checked.

When differential sync shoud be disabled
Differential synchronization can (especially in reconciliation mode) significantly increase system speed. Normally there is no reason for it not to be activated.
The only situation where differential synchronization cannot be used is when we require all synchronized entities to be saved because of project-specific processors that are linked to the save event.
Events
Synchronization makes use of the standard mechanism of events in IdM, adding three new events:
- SysSyncItemLog.START_ITEM
and new processors:
* synchronization-item-processor - The processor in its default state performs the synchronization of each of the synchronized elements (SynchronizationService.doItemSynchronization).
Scheduled task
For the scheduled activation of the synchronization, the task SynchronizationSchedulableTaskExecutor has been created which has the uuid as an input parameter of the configuration of the running synchronization.
The task will read the synchronization configuration according to the entered uuid, and will launch it in the same way as a direct launching from the overview of the configured synchronization configurations on the system detail.
After the launching, it is possible to observe and possibly stop the running synchronization from the overview of running tasks. When the task is finished, the final log can be seen not only in the synchronization agenda on the system, but also in the overview of all tasks.
Removing "wish"
(since 9.3.0)
The attribute "wish" of the SysSystemEntity marks entities, which were created by provisioning, but which were never successfully provisioned (see more in provisioning operation life cycle). Most common reasons of this situation are:
- IdM tried to create an account with an identifier, which already existed in the target system. Reusing (auto mapping) already existing accounts is disabled for security reasons by
idm.sec.acc.provisioning.allowedAutoMappingOnExistingAccount=truein the application properties, so the Create operation failed. - The system was read-only when the system entity was created, so provisioning didn't tried to create the account at all.
In both situations, the corresponding Create operation is waiting for some manual action in the provisioning queue, or it was already deleted by admin.
Since synchronization in principle knows, which accounts (identifiers) really exist on the target system, it removes "wish" from their corresponding system entities to correct the information in IdM. However, synchronization removes "wish" only if it is safe - so it won't lead to any unwanted linking (auto mapping) of the accounts. Therefore, "wish" is removed in the following situations:
- Missing entity, Unlinked - independently of the configured action.
- Reason: The system entity wasn't linked to any IdM entity before this synchronization. It's just some relic of previous operations in IdM. The identifier on the system exists, so we can correct the information that it is only "wish" (because it really exists).
- Linked - only if the action Update entity or Update account is configured and the property
idm.sec.acc.provisioning.allowedAutoMappingOnExistingAccountistrue.- Reason: The system entity is linked to an IdM entity. By removing "wish", we would effectively do auto mapping, because following provisioning attempts would be Update and not Create. So we can remove "wish" only if auto mapping is allowed.
User type (projection)
Since version 10.3.0, identity synchronization supports sync of a user type:
- On the attribute detail, select the entity filed User type (IdmFormProjectionDto).
- The output of the transformation from the system can be a user-type identifier or its code (the IdmFormProjectionDto object).
User type provisioning is also supported from this version:
- On the attribute detail, select the entity filed User type (IdmFormProjectionDto).
- Input value in transformation to the system is user type object (IdmFormProjectionDto).
For provisioning a code of user type, you can use this example:
if (attributeValue != null) {
return attributeValue.getCode();
}